Text Classifier Network
In this post I present my first attemp to develop a full textual neural network and explains all its principles.




- introduction
- Installation of the packages
- Train a text classifier from a pretrained model
- Train a text classifier using the ULMFit approach
- Conclusion of the project
introduction
The main goal of this projesct is to develop a deep learning project using Pytorch and Fast.ai. After PyTorch came out in 2017 it has become the world's fastest-growing deep learning library and is already used for most research papers at top conferences. This is generally a leading indicator of usage in industry, because these are the papers that end up getting used in products and services commercially. PyTorch is considered nowadays the most flexible and expressive library for deep learning. It does not trade off speed for simplicity, but provides both.
PyTorch works best as a low-level foundation library, providing the basic operations for higher-level functionality, the fast.ai library is the most popular library for adding this higher-level functionality on top of PyTorch (there's even a peer-reviewed academic paper about this layered API) and bearing in mind these reasons, these were the tools that I found most appropriate for this project.
Here, we will see how we can train a model to classify text (here based on their sentiment). First we will see how to do this quickly in a few lines of code, then how to get state-of-the art results using the approach of the ULMFit paper, using the IMDb dataset from the paper Learning Word Vectors for Sentiment Analysis, containing a few thousand movie reviews. In addition , I am planning to add later also a mid-level API for data collection fromn the wikitext dataset, inspired by the teaching tutorial of fast.ai from github.
Installation of the packages
First, it is important to clarify that you can use fastai without any installation by using Google Colab.If you want to run things locally, you can install fastai on your own machines with conda (highly recommended), as long as you're running Linux or Windows (NB: Mac is not supported).
to proceed with installation in Anaconda, run the following command line:
conda install -c fastchan fastai anaconda
To install with pip, use: pip install fastai. If you install with pip, you should install PyTorch first by following the PyTorch installation instructions, which for my setup design consists on only running the following command line:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
but you can use the mentioned website to configure your installation command line according to your setup settings.
from fastai.text.all import *
path = untar_data(URLs.IMDB)
path.ls()
(path/'train').ls()
The data follows an ImageNet-style organization, in the train folder, we have two subfolders, pos and neg (for positive reviews and negative reviews). We can gather it by using the TextDataLoaders.from_folder method. The only thing we need to specify is the name of the validation folder, which is "test" (and not the default "valid").
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
We can then have a look at the data with the show_batch method:
dls.show_batch()
We can see that the library automatically processed all the texts to split then in tokens, adding some special tokens like:
-
xxbosto indicate the beginning of a text -
xxmajto indicate the next word was capitalized
Then, we can define a Learner suitable for text classification in one line
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
Here, we have used the AWD LSTM architecture, drop_mult is a parameter that controls the magnitude of all dropouts in that model, and we use accuracy to track down how well we are doing. We can then fine-tune our pretrained model as can be seen below
learn.fine_tune(4, 1e-2)
As you can see from the progress of the last line, our model is doing pretty good until now! In order to quantize through objective criteria how well the model is performing, we can use the show_results method as it follows
learn.show_results()
And we can predict on new texts quite easily from now on as our model has already undergone more advanced training
learn.predict("I really liked that movie!")
Here we can see the model has considered the review to be positive. The second part of the result is the index of "pos" in our data vocabulary and the last part is the probabilities attributed to each class (99.1% for "pos" and 0.9% for "neg").
Using what has been done so far, you can even write your own mini movie review, or copy one from the Internet, and we can see what this model thinks about it by performing the same command that we run before!
For the curious ones: Using the data block API
We can also use the data block API to get our data in a DataLoaders. This is a bit more advanced, The intention with this is just to refine our work a little more so far in order to learn details about the structure of the data and the way it will be stored.
A datablock is built by giving the fastai library a bunch of information:
- the types used, through an argument called
blocks: here we have images and categories, so we passTextBlockandCategoryBlock. To inform the library our texts are files in a folder, we use thefrom_folderclass method. - how to get the raw items, here our function
get_text_files. - how to label those items, here with the parent folder.
- how to split those items, here with the grandparent folder.
imdb = DataBlock(blocks=(TextBlock.from_folder(path), CategoryBlock),
get_items=get_text_files,
get_y=parent_label,
splitter=GrandparentSplitter(valid_name='test'))
This only gives a blueprint on how to assemble the data. To actually create it, we need to use the dataloaders method:
dls = imdb.dataloaders(path)
Train a text classifier using the ULMFit approach
The pretrained model we used in the first stage of this project is called a language model. It was pretrained on Wikipedia on the task of guessing the next word, after reading all the words before. We got great results by directly fine-tuning this language model to a movie review classifier, but with one extra step, we can do even better: the Wikipedia English is slightly different from the IMDb English. So instead of jumping directly to the classifier, we could fine-tune our pretrained language model to the IMDb corpus and then use that as the base for our classifier.
One reason, of course, is that it is helpful to understand the foundations of the models that you are using. But there is another very practical reason, which is that you get even better results if you fine tune the (sequence-based) language model prior to fine tuning the classification model. For instance, in the IMDb sentiment analysis task, the dataset includes 50,000 additional movie reviews that do not have any positive or negative labels attached in the unsup folder. We can use all of these reviews to fine tune the pretrained language model — this will result in a language model that is particularly good at predicting the next word of a movie review. In contrast, the pretrained model was trained only on Wikipedia articles.
The whole ideia of this stage can be summarized by this picture:
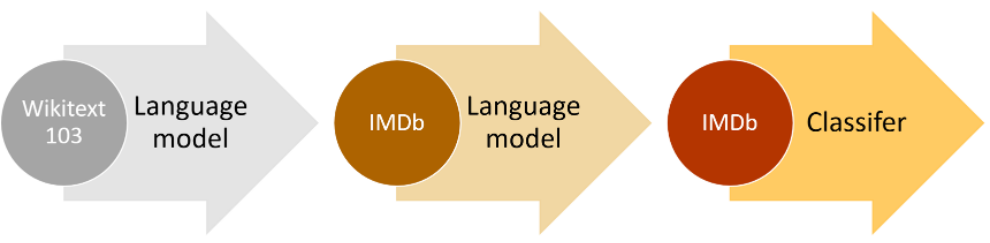
We can get our texts in a DataLoaders suitable for language modeling very easily:
dls_lm = TextDataLoaders.from_folder(path, is_lm=True, valid_pct=0.1)
We need to pass something for valid_pct otherwise this method will try to split the data by using the grandparent folder names. By passing valid_pct=0.1, we tell it to get a random 10% of those reviews for the validation set.
We can have a look at our data using show_batch. Here the task is to guess the next word, so we can see the targets have all shifted one word to the right.
dls_lm.show_batch(max_n=5)
Then we have a convenience method to directly grab a Learner from it, using the AWD_LSTM architecture like before. We use accuracy and perplexity as metrics (the later is the exponential of the loss) and we set a default weight decay of 0.1. to_fp16 puts the Learner in mixed precision, which is going to help speed up training on GPUs that have Tensor Cores.
learn = language_model_learner(dls_lm, AWD_LSTM, metrics=[accuracy, Perplexity()], path=path, wd=0.1).to_fp16()
By default, a pretrained Learner is in a frozen state, meaning that only the head of the model will train while the body stays frozen. We show you what is behind the fine_tune method here and use a fit_one_cycle method to fit the model:
learn.fit_one_cycle(1, 1e-2)
This model takes a while to train, so it's a good opportunity to talk about saving intermediary results.
One should know that the state of your model can easily be saved like so:
learn.save('1epoch')
It will create a file in learn.path/models/ named "1epoch.pth". If you want to load your model on another machine after creating your Learner the same way, or resume training later, you can load the content of this file with:
learn = learn.load('1epoch')
We can them fine-tune the model after unfreezing:
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3)
Once this is done, we save all of our model except the final layer that converts activations to probabilities of picking each token in our vocabulary. The model not including the final layer is called the encoder. We can save it with save_encoder:
learn.save_encoder('finetuned')
Jargon:Encoder: The model not including the task-specific final layer(s). It means much the same thing as body when applied to vision CNNs, but tends to be more used for NLP and generative models.
Before using this to fine-tune a classifier on the reviews, we can use our model to generate random reviews: since it's trained to guess what the next word of the sentence is, we can use it to write new reviews:
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
preds = [learn.predict(TEXT, N_WORDS, temperature=0.75)
for _ in range(N_SENTENCES)]
print("\n".join(preds))
dls_clas = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test', text_vocab=dls_lm.vocab)
The main difference is that we have to use the exact same vocabulary as when we were fine-tuning our language model, or the weights learned won't make any sense. We pass that vocabulary with text_vocab.
Then we can define our text classifier like before:
learn = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
The difference is that before training it, we load the previous encoder:
learn = learn.load_encoder('finetuned')
The last step is to train with discriminative learning rates and gradual unfreezing. In computer vision, we often unfreeze the model all at once, but for NLP classifiers, we find that unfreezing a few layers at a time makes a real difference.
learn.fit_one_cycle(1, 2e-2)
In just one epoch we get the same result as our training in the first section, not too bad! We can pass -2 to freeze_to to freeze all except the last two parameter groups:
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2))
Then we can unfreeze a bit more, and continue training:
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3))
And finally, the whole model!
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3))
Conclusion of the project
So far, I hope the power of artificial intelligences that use predefined python libraries like pytorch has become clear. With simple scripts like the one developed here for didactic purposes, we can create models capable of predicting market behavior, human writing patterns, and even performing detailed analyzes on databases that would cost us many hours of relatively automated work, which can be saved with a simple implementation like the one shown here.
Ihope you like it, and feel free to try on your own machine and tell me later your thoughts on this project, as well as any suggested modifications, everything can be discussed in the comments of this push on github or through private conversations in my email:
ruben.esteche@ufpe.br
or
rubenesteche@hotmail.com